
Conventional wisdom says that using an Image is always faster than a Retrieve operation. Is it true? Well, it’s complicated. Today we’re going to run some benchmark tests and find out when when using a Retrieve in a plugin is actually faster than an Image.
I recently worked on a Dynamics 365 project where my client wanted custom templates to quickly respond to customers – similar to email templates. To make the responses tailored to the customer we build a field substitution mechanism, so the template would be built as:
Hi {!contact:firstname},
and when the plugin runs and the text is evaluated it becomes:
Hi Aiden,
The implementation was straightforward with the only wrinkle coming when it was time to register my plugins and associated Images. The fields that the Plugin needs can be different for each template and I can’t know them in advance, so I have to include all fields in my Image. When you select the option to include all fields to an image you’ll get the following warning.
This is the most aggravating “helpful” message I’ve seen in some time. Not only does it flip the traditional Yes/No on a confirmation (so you have to click No to proceed), but the message implies if you include the whole image then you can’t care about performance, and that there’s no valid reason where including the whole image is the most performant way. While I was complaining about the message a colleague suggested it might be faster to skip the Image and instead, figure out what fields I need in the plugin and perform a Retrieve to just get those fields. This was the impetus behind seeing if there’s ever a case where using a full image isn’t the fastest way to meet this need.
Objective
With this performance benchmark test there were several questions I wanted to answer:
- Is there really a performance difference using Images vs a Retrieve?
- Does that difference change based on the number of fields?
- Does is matter if the fields have data or if they’re empty?
- Can it ever be faster to Retrieve a single field instead of using an Image?
Setup
Note: All the code and solutions needed to perform this test are available on GitHub at https://github.com/akaskela/Performance-Benchmarks
The test consisted of two entities:
- A ‘Benchmark Subject’ entity, which is the subject of the test. This entity has:
- 500 text fields to represent a lot of data on a large entity
- 16 fields trigger fields – each trigger field corresponds to a different plugin to run
- A ‘Benchmark Initiator’ entity, which controls the test and reports the results. It has:
- Subject Field to Set -text input, the trigger field on the Subject
- Number of Evaluations – how many times should it test the record
- Populate Data – If the subject test fields should contain data or be blank
- MS per Evaluation – (Output) the mean time for each evaluation.
- All Operation Times – (Output) a comma separated list off the time for each operation in the test.
There are 16 nearly identical plugins on the Benchmark Subject entity, corresponding to each of its 16 trigger fields. The plugins are designed to get the value from 1 or more text fields, either by performing a Retrieve operation or by getting them from the image.
The tests look at performing this basic function with 1, 5, 10, 25, 50, 100, 250 and 500 fields. The Retrieve plugins will get those fields in a single request, and the Image plugins will have only those fields specified in the Image input dialog.
The 16 plugins were all configured as synchronous, Post-Operation steps.
Method
To control for internet speeds, the timed tests were performed by a plugin on the Benchmark Initiator.
A single evaluation is performed by creating a Benchmark Initiator record with the Subject Field to Set (afk_triggerretrieve100), and then number of times to perform the test (40). A synchronous Pre-Create operation on the Initiator gets the average time to perform that operation by doing the followings:
- Create a new Benchmark Subject record
- If the field ‘Populate Data’ is true, populate all 500 text fields with the word “Text”. Otherwise don’t populate any data.
- Note: I originally set these with a Guid but the record size was too large for the database.
- For each time the test is performed (40)
- Set the Benchmark’s field to set to ‘true’
- Restart the timer
- Update the Benchmark record to run the corresponding operation
- Add the elapsed time to a list
- Set the “MS per Evaluation” to the sum of operation times, divided by the number of tests.
- Set “All Operation Times” to a comma separated list of the 40 individual times.
In the example above, we get an average time to run the plugin retrieving 100 fields performed on 40 records, along with the individual times for each of the 40 operations.
This is fine for a single manual test, but there are two problems. First, it’s a small sample size and pretty meaningless without multiple runs. Second, if the tests aren’t performed close to the same time then it may be affected by noisy neighbors or other changes to the cluster the organization lives in. To address both those problems the main test application (also available in the GitHub repo) does the following:
- Loop over this 125 times
- Perform the plugin test on Image 1 for 40 records, with data, and log the individual operation times
- Perform the plugin test on Image 1 for 40 records, without data, and log the individual operation times
- Perform the plugin test on Retrieve 1 for 40 records, with data, and log the individual operation times
- Perform the plugin test on Retrieve 1 for 40 records, without data, and log the individual operation times
- { repeat for 5, 10, 25, 50, 100, 250, 500 }
- For each distinct operation and data/no data pair, compile a list of all times and log the mean, median, and standard deviation.
Since we’re alternating between Image, Retrieve, with and without data, throughout the test any noisy neighbor scenarios would be spread across the entire data set to keep the operations on a level playing field.
Results
The final data contains the average time of 5,000 operations against 32 different configurations, for a total of 160,000 operations. Note: All times in these charts use the median time to reduce the effect of extreme outliers.
First, let’s take a look at comparing Image and Retrieve with data.
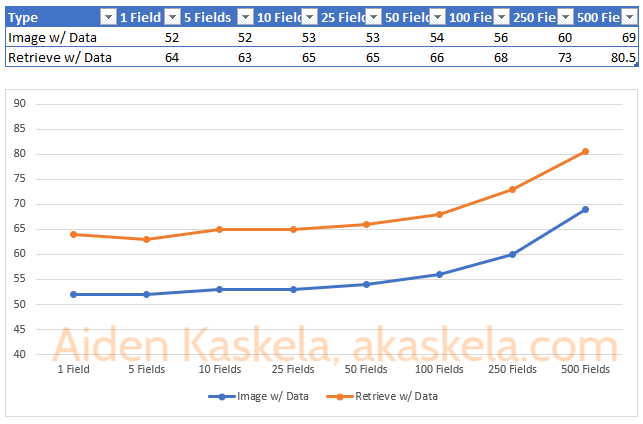
We can see a few observations right off the bat:
- For a given number of fields, getting the value from the Image is always faster than retrieving it.
- Having a few extra fields in your Image or Retrieve is fine. Below 25 fields there’s virtually no difference in performance.
- If you continue to add fields, especially as that number gets very large, it can make a difference. Here, going from 1 field to 500 fields makes the operation using the Image 32% slower and the Retrieve is 25% slower.
Now, let’s take a look at the same information where the records do not contain data.
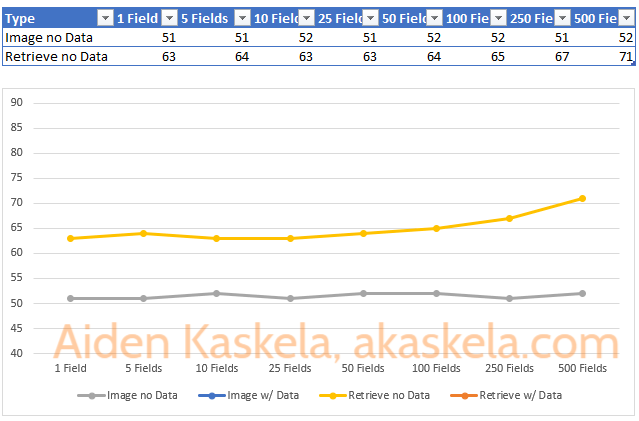
In this chart we draw the following conclusions:
- Again, getting data from the Image is always faster than a Retrieve operation, and as you add more fields the difference only increases.
- When using an Image, including fields where the record does not contain data has no impact on actual run time.
- When retrieving a record, including fields in the ColumnSet does have an impact on the performance even if there is no data. The operation is 12% slower when requesting 500 fields compared to 1 field. The performance impact is not as significant as when there is data. This result is intuitive as you would expect more data transfer to take more time.
Looking at these two charts independently we would be tempted to say an Image is always faster, and in an apples-to-apples scenario that’s true. But when we overlay the charts we can see something interesting:
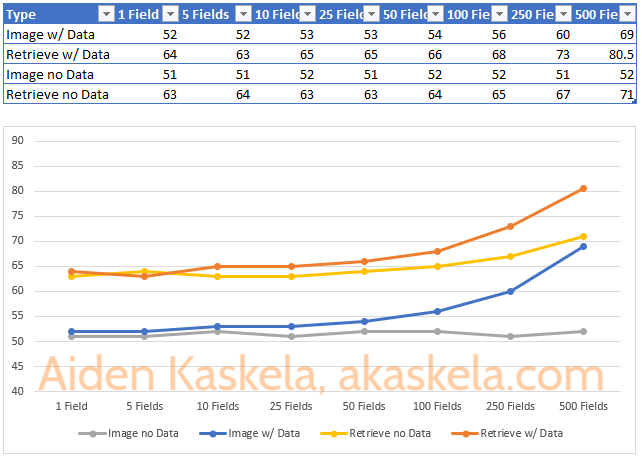
The first observation is that at 500 fields, performing a Retrieve on a record with no data is almost the same as using an Image with full data. Based on the trend line it looks like another 50 fields or so may close the gap. This is a pretty extreme scenario, and in practice I would expect some of those fields to have data and the Image would likey still be faster.
What’s most interesting though, and the answer to the question that started this whole journey, is that there is a point where we’re able to Retrieve a few fields from a record faster than if we were to pass in an Image with a lot of fields that had data. In this chart, it’s around 64ms (350 populated fields in an Image vs 5 in a Retrieve).
Conclusion
Using an Image always gives better performance than performing an identical operation on a retrieve and should be the default option for implementing plugins. However, given the scenario where you have to choose between passing in a full Image or performing a Retrieve for a few fields, you should carefully evaluate not just the number of fields you expect on the record but the number that you’d reasonable expect to be populated on a typical record. With that information in hand you’re able to make the best decision on if you should make an unusual implementation decision that ends up giving you the best performance possible.
Additional Testing Notes
All testing code and solutions are available on GitHub to reproduce my work (https://github.com/akaskela/Performance-Benchmarks).
For the sake of thoroughness I wanted to include the Standard Deviation for each operation but due to extreme outliers this was a useless number. I largely compensated for that by using the median values and excluding the outliers would have brought the overall numbers down, but my expectation is that it would’ve have a negligible impact on the results.
Additional analysis could be performed with 25/50/75% of the data populated to see where the break even point is for records populated at those percentages. My expectation is that they’d fall proportionally between 0 and 100% but that’s why we do experiments.
